The current technological landscape is driven by massive data streams. To understand how modern artificial intelligence perceives, reasons, and acts, we must trace the pathway from raw data engineering up to autonomous multi-agent cognitive architectures.
1. The Foundations: Data Science, Big Data, and Machine Learning
Data Science is the overarching discipline that combines domain expertise, programming skills, and mathematical framework configurations to extract meaningful insights from data. When these datasets grow so massive, fast, and varied that traditional relational databases can no longer process them, they enter the realm of Big Data, requiring specialized distributed computing tools like Apache Spark or Hadoop.
Machine Learning (ML) is the engine inside data science. Instead of a programmer writing rigid, explicit rule-based algorithms, ML provides statistical models with the ability to look at data inputs, discover latent mathematical regularities on their own, and improve their predictive accuracy over time.
2. The Core Pillars of Machine Learning
Machine Learning is structurally categorized into three primary learning paradigms based on the nature of the feedback loop provided to the model during its training phase:
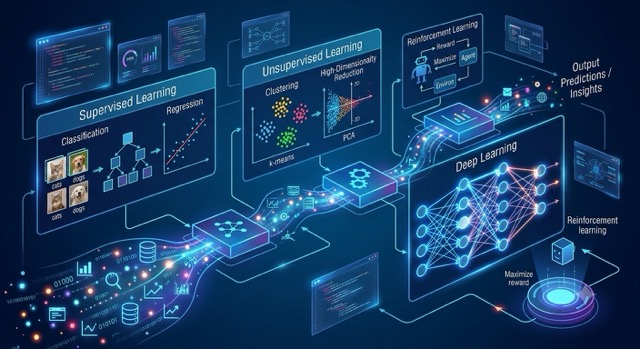
A. Supervised Learning
In Supervised Learning, the model learns from labeled training data containing explicit input-output mappings. The system optimizes its weights to map an input vector $X$ to a known ground-truth target vector $Y$.
- Linear Regression (Continuous Prediction): Predicts a real-valued output by computing a weighted linear combination of input features. The goal is to minimize the Residual Sum of Squares (RSS). The objective function is formulated as: $$RSS = \sum_{i=1}^{n} (y_i - (\beta_0 + \beta_1 x_i))^2$$
- Logistic Regression (Classification): Used for binary outcomes by passing a linear combination of features through the non-linear Sigmoid function, mapping any real value between 0 and 1: $$P(Y=1|X) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 X)}}$$
- Support Vector Machines (SVM): Constructs an optimal hyperplane in a high-dimensional space that maximizes the geometric margin between different data classes.
B. Unsupervised Learning
In Unsupervised Learning, the training dataset lacks explicit labels or target outcomes. The model parses the data to uncover hidden patterns, natural groupings, or structural anomalies within the input features.
- K-Means Clustering: Partitioning data points into $K$ distinct clusters by minimizing the total distance between data points and their respective cluster centers (centroids). The objective function is: $$J = \sum_{j=1}^{K} \sum_{i=1}^{n} ||x_i^{(j)} - c_j||^2$$
- Principal Component Analysis (PCA): A dimensionality reduction technique that lineary projects high-dimensional feature spaces onto lower-dimensional subspaces while retaining maximum statistical variance.
C. Reinforcement Learning (RL)
Reinforcement Learning relies on behavioral psychology. An autonomous agent navigates an environment, observes states ($S$), executes actions ($A$), and receives scalar rewards or penalties ($R$). The objective is to discover an optimal policy ($\pi$) that maximizes cumulative expected future rewards over time.
Q-Learning is a foundational model-free RL algorithm that updates its state-action value table using the Bellman Equation: $$Q(s, a) \leftarrow Q(s, a) +$$ $$ \alpha [r + \gamma \max_{a'} Q(s', a')- Q(s, a)]$$
3. Deep Learning and Neural Network Topologies
Deep Learning is a specialized subset of Machine Learning that utilizes multi-layered artificial neural networks inspired by biological brain architectures. Standard Artificial Neural Networks (ANNs) consist of an Input Layer to receive features, multiple Hidden Layers that extract abstract representations, and an Output Layer that generates final predictions.
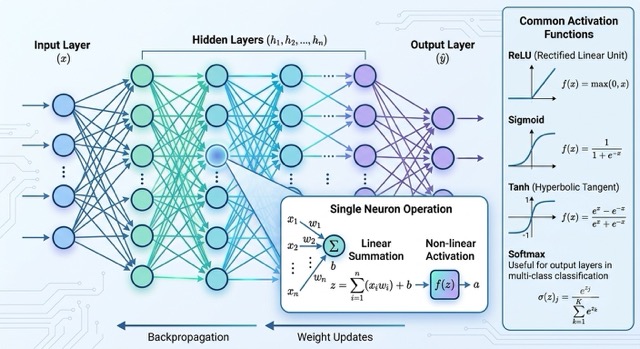
Each synthetic neuron processes information by calculating the dot product of its incoming vector and learned weights ($W$), adds a bias metric ($b$), and routes that scalar sum through a non-linear Activation Function (such as ReLU: $f(x) = \max(0, x)$ or Sigmoid). This non-linearity allows the network to approximate complex, highly non-linear functions.
To learn, the network calculates errors at the output layer using a Loss Function. It then uses **Backpropagation** to pass the calculated error gradient backward through the network topology using the chain rule of calculus. An optimization engine, like Stochastic Gradient Descent (SGD) or Adam, uses these gradients to update the weights, minimizing overall predictive error.
4. Advanced Deep Learning Paradigms: The Architectural Matrix
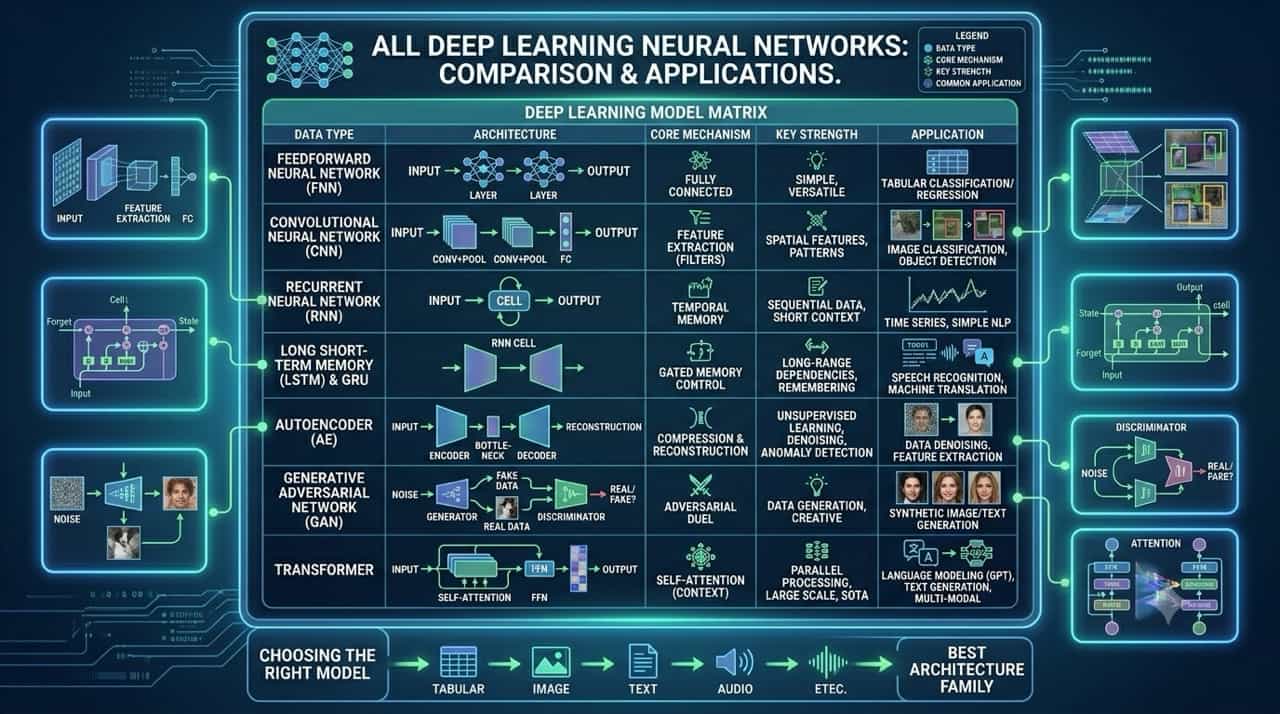
Different industrial and cognitive problems require highly specialized neural network topologies. Knowing which architecture to deploy is the defining skill of a deep learning engineer:
- Feedforward Neural Networks (FNN): The foundational architecture. Data moves in a single direction from input to output through fully connected layers. They are simple, versatile, and best suited for standard tabular data classification and regression tasks.
- Convolutional Neural Networks (CNN): The undisputed king of computer vision. Instead of fully connected layers, CNNs use sliding filters to extract spatial features (like edges, textures, and shapes) and pooling layers to reduce dimensionality. They are the standard for image classification, object detection, and facial recognition.
- Recurrent Neural Networks (RNN): Designed specifically for sequential data. RNNs feature internal temporal memory loops that pass previous hidden states forward into the next step. They excel at processing historical time-series data and simple natural language tasks where short-term context matters.
- Long Short-Term Memory (LSTM) & GRU: Traditional RNNs "forget" early information in long sequences (the vanishing gradient problem). LSTMs solve this by introducing complex gated memory controls that can selectively remember or forget long-range dependencies. They are the backbone of speech recognition and complex machine translation.
- Autoencoders (AE): An unsupervised learning architecture shaped like an hourglass. The network compresses input data into a tiny bottleneck layer (the encoder) and then attempts to perfectly rebuild the original data from that bottleneck (the decoder). They are heavily used for data denoising, anomaly detection, and feature extraction.
- Generative Adversarial Networks (GAN): An architecture built on a high-stakes duel. A "Generator" network creates fake data (like a synthetic face), while a "Discriminator" network tries to catch the fake. They train against each other until the Generator produces data so realistic it fools human eyes. GANs are the core of deepfakes and high-fidelity synthetic media generation.
- Transformers: The architecture that triggered the modern AI boom. By utilizing the Self-Attention mechanism, Transformers look at every piece of data in a sequence simultaneously rather than one by one, enabling massive parallel processing. They are the foundational architecture for all state-of-the-art Large Language Models (like GPT and Gemini) and multi-modal generation.
5. The Modern Era: Generative AI and Agentic Frameworks
Generative AI (GenAI) marks a shift from models that classify or analyze data to models that create completely new data. By leveraging pretrained Transformer-based foundational architectures, systems like GPT, Gemini, and Claude analyze input patterns to generate text, images, video, and code on demand.
However, the industry has rapidly advanced past passive text completion into the territory of Agentic AI. While early GenAI chatbots relied on a simple human prompt-response loop, Agentic AI architectures operate as proactive, goal-oriented digital entities. Agentic systems feature three core engineering blocks:
- Planning and Reasoning: The agent takes a complex goal, breaks it down into explicit sub-tasks, and handles multi-step problems over long horizons.
- Tool Utilization: The system identifies when it lacks information, autonomously calling external APIs, executing Python code sandboxes, or querying databases to retrieve real-time data.
- Multi-Agent Workflows: Specialized AI entities operate together in collaborative loops—such as an engineering system where an AI software developer, an AI security tester, and an AI deployment manager critique and refine code logic autonomously before pushing it live.
6. Real-World Applications
The convergence of these data paradigms is transforming industries:
- Biotech and Medicine: Deep neural architectures accelerate protein folding tracking and compress preclinical drug discovery timelines significantly.
- Autonomous Systems: Vision-Language-Action models convert live visual feeds from security cameras or humanoid robot arrays directly into precise physical motor actions, enabling real-world spatial reasoning.
- Enterprise Automation: Asynchronous agentic networks process unstructured legal, financial, and code data pipelines, shifting roles from manual operations to system supervision.
From basic regression curves to distributed neural networks and autonomous multi-agent systems, the underlying goal remains unchanged: transforming raw data data into predictable, intelligent action.